

케이쉴드 인원들과 술을 먹다가 전 케이쉴드 매니저 현 동네친구가 된 친구에게 코딩하기 싫다고 찡찡대니 친구가 스크립트 언어부터 시작하는게 어떻냐고 물어보면서 간단하게 크롤링하는 방법을 보여주었는데 먼가 멋있어 보여 나도 하고 싶다 숙제 내달라고 하여 시작된 python...
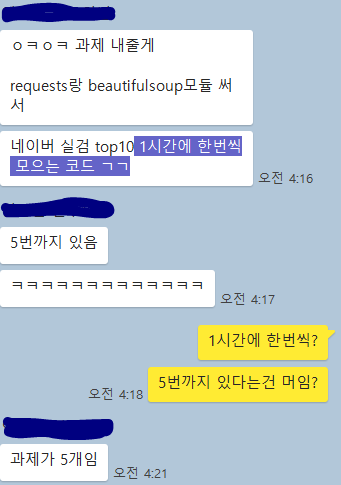
5시에 집들어가면 강아지가 짖어 카페가서 공부하겠다고 하니 숙제를 내줘버렸다...
일단 한다고 했으니 해보도록 하겠다.
크롤링이란?
크롤링이란 Web상에 존재하는 Contents를 수집하는 작업이다. 쉽게 말해 웹상에서 내가 원하는 정보를 가져오는 작업이라고 생각하면 된다.
기본적으로 크롤링을 하려면 requests 모듈과 BeautifulSoup 모듈을 import 해야한다.
먼저 파이썬을 깔고 python을 키고 import로 requests를 해 보았다.

이런 에러가 뜬다.
requests라는 모듈이 존재하지 않아서 뜨는 에러라고 하였다.
pip install requests
pip install requests를 하여 requests 모듈을 다운받아야 한다고 하였으니 requests 모듈을 다운 받아 보았다.
이미 설치를 완료하기는 하였지만 혹시나 설치 도중에 빨간줄이 뜨면서 에러가 뜬다면 관리자 모드에서 다운 받아라 그럼 될 것이다.
import requests
다운을 받은 후 다운받은 requests 모듈을 불러오려고 하였다.
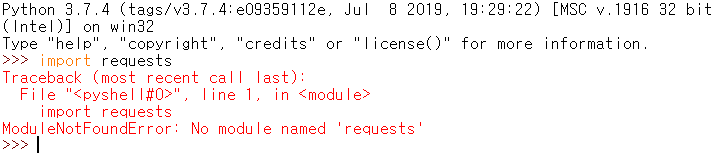
모듈이 없단다.
설치가 잘못되었나 확인해보려고 cmd 창을 켜보면
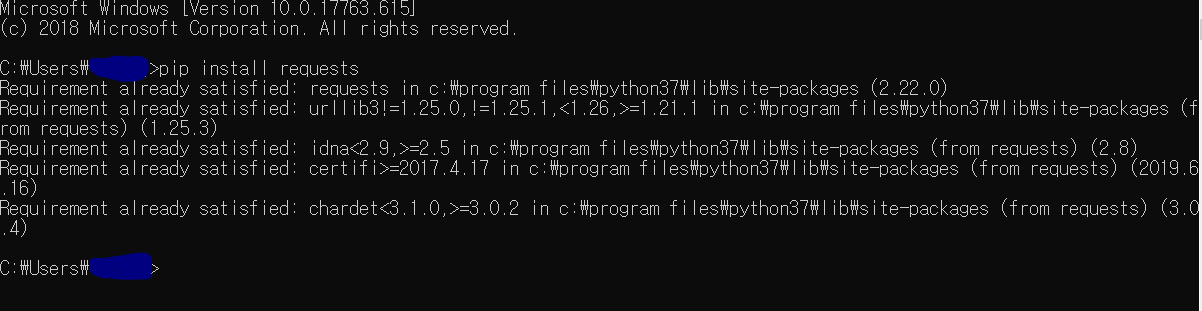
이미 설치가 되어있다고 한다.
그래서 무엇이 문제인가 확인해보니 64bit를 켰어야 하는데 32bit를 키고 있었다.
그래서 64-bit로 키고 다시 import를 해보니 제대로 작동된다.
form bs4 import BeautifulSoup
그 후 BeautifulSoup를 import 해보았다.
requests와 달리 앞에 from bs4가 붙는데 이유는 잘 모르겠다.
res = request.get('https://www.naver.com')
requests 라이브러리를 통해 HTML 페이지를 요청하는 코드이다.
나의 목적은 naver.com에 있는 실시간 검색어를 크롤링하는 것이기 때문에 다음과 같이 res 변수에다가 네이버 주소를 넣어 페이지를 요청하였다.
html = res.text
다음으로 네이버에 있는 코드를 가져오기 위해 다음과 같이 입력해준다.
다음과 같이 입력하면 html변수 안에는 네이버에 코드가 저장되어 있다.
print(html)결과

다음과 같이 입력하면 naver의 html 코드가 다 출력된다.
soup = BeautifulSoup(html,'html.parser')
네이버 html 코드도 가지고 왔고, BeautifulSoup를 import도 했다면 다음과 같은 코드를 입력해준다.
다음 코드는 python에게 'html 코드로 작성되어 있으니 너도 html코드로 이해해라'라고 해주는 코드라고 한다.
첫번째 인자는 내가 html 코드를 저장한 변수이므로 변수명을 다르게 했다면 변수명을 적어줘야한다.
soup또한 다른 변수명으로 적어도 된다.
두번째 인자는 어떤 parser를 이용할지 명시해주는건데 html.parser는 python에 내장되어 있는 parser이다.
다음과 같이 입력을 하였으면 네이버에 가서 우리가 크롤링을 해야하는 코드를 확인해야한다.
네이버에 들어가서 F12를 누르게 되면

다음과 같이 뜨는데 여기서 형광펜을 칠한 부분을 누르고 나서 아이콘을 누르면 그 아이콘에 대한 코드로 이동시켜준다.
내가 보고싶은 코드는 실시간 검색어 부분이므로 실시간 검색부분을 눌러주면

다음처럼 코드를 이동시켜준다.
코드를 계속 확인하다보면 순위부분 숫자는 속성값이 "ar_h"이 순위 뒤 실시간 검색어는 "ar_k"로 속성값이 저장되어 있다.
그렇기에 "ar_k"로 되어있는 정보만 빼오면 실시간 검색어 정보만 빼올 수 있을 것 같았다.
그래서 select문을 사용하기로 하였다.
soup.select('span[class="ah_k"]')
코드를 입력하기 전에 select문을 사용하는 방법부터 설명하겠다.
select문은 html내에 필요한 부분 선택하는 방법인데
변수명.select('원하는 정보)
변수명.select('원하는 정보')
변수명.select('태그명')
변수명.select('.클래스명')
변수명.select('#아이디명')
변수명.select('#태그명[속성명=속성값]')이런방식으로 사용하면 된다.
naver의 html 코드를 보면 태그는 'span'을 사용하고 있고 속성명은 'class', 속성값은 'ah_k'를 사용하고 있기에 다음과 같이 입력해주었다.
입력결과)

잘 보이지는 않겠지만 1위부터 20위까지 실검의 결과가 2번씩 나오고 있다.
매우 당황스러웠다.
그래서 다른 방법을 사용해보기로 했다.
soup.select('a[data-clk="lve.keyword"]')
html 코드를 좀 더 확인해 본 결과 속성명으로 data-clk를 사용하고 있는 것을 확인하여 다음과 같이 입력해 보았다.
입력을 해보니

먼가 보기는 좀 더 깔끔해진 것 같지만 결과적으로 실검이 두번씩 나오는 것은 변하지가 않았다.
그래서 고민을 해봤다.
그러다가 크롤링 결과를 변수(배열)에 저장하고 그 값 중 하나만 출력해보았다.

실검 3위의 결과만 출력이 되는것이다.
그래서 생각한게 for문을 이용해서 1~20까지 범위를 설정해놓으면 한번씩만 출력될 것 같았다.
야매 같긴 하지만 파이썬을 처음해보는 입장으로써 최선의 방법이 이것밖에 없는 것 같았다.
d = soup.select('a[data-clk="lve.keyword"]')
다음과 같이 select 문을 이용해 html 코드를 선택하고
for i in range(0,20) : print(d[i])
다음과 같이 범위를 설정해준 다음 엔터를 누르면

다음과 같이 1위 부터 20위까지 한번씩만 출력이 된다.
#내가 짠 코드
import requests
from bs4 import BeautifulSoup
res = request.get('https://www.naver.com')
html = res.text
soup = BeautifulSoup(html,'html.parser')
d = soup.select('a[data-clk="lve.keyword"]')
for i in range(0,20) :
print(d[i])
매우 야매적인 방식이지만 python을 구글링으로만 공부하다 보니 이 방식 이외에 더 좋은 방법을 모르겠다....
좀 더 공부한다음에 더 괜찮은 방식이 생긴다면 그 방식을 다시 포스팅 하도록 하겠다.
'python?' 카테고리의 다른 글
| python으로 엑셀파일 열고 쓰기(with pandas) (2) | 2019.10.19 |
|---|---|
| 파이썬으로 엑셀 다루기(完) (2) | 2019.10.07 |
| 파이썬으로 엑셀 다루기(사용자에게 값 받고 찾아주기) (2) | 2019.08.19 |
| 파이썬으로 엑셀 다루기(사용자에게 받은 값의 셀 전체 출력하기) (0) | 2019.08.18 |
| 파이썬으로 엑셀 다루기(파일 읽기, 쓰기) (6) | 2019.08.15 |